爬虫技术总结
做了几个月爬虫,也积累了一些经验,爬虫的技术相对比较零散,这里简单汇总一下。
爬虫技术栈
- 从获取网页的内容谈起
- 请求与下载
- 浏览器保存
- wget/curl命令行
- requets包
- 内容过滤
- 模式匹配
- BeautifulSoup
- 更高级的需求
- 批量
- 自动
- 监控
- 分布式
- 爬虫的诞生
- 爬虫架构
- 基本架构
- 下载
- 存储
- 高级架构
- 队列
- 调度
- 下载
- 过滤
- 存储
- 更高级的架构
- master/schedule
- queue/communication/filter
- worker/download
- processer/save
- 基本架构
- 一个网络请求
- URL/API
- Protocol
- http
- https
- Method
- get
- post
- Headers
- User+Agent
- Authorizition
- Referer
- Accept+Encoding
- Cookies
- 请求信息的获取
- 公开API
- Web端
- chrome development tools
- Mobile端
- charles(mac/pc)
- Replica(ios)
- Reverse Engineering
- PC端
- charles
- wireshark
- 爬虫框架——scrapy
-
scrapy架构
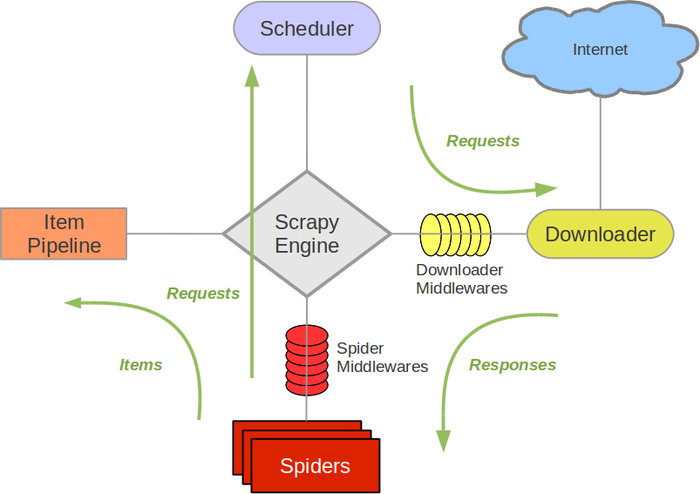
-
scrapy基本用法
- items
- spider
- xpath
- pipline
- process
-
scrapy高级用法
- scrapyd管理
- callback机制
- 重写Request方法
- Selector构造
- 分布式部署(celery/redis)
- middleware定制
-
- 爬虫架构
- 关于反爬虫
- 反爬虫的哲学
- 不能完全屏蔽爬虫,只能尽可能提高爬取成本
- 常见的反爬虫机制
- https
- charles + ssl证书
- 验证码
- 打码平台(机器/人工)
- Tesseract
- 链接签名验证
- Reverse Engineering
- 其他工具(youtube-dl/you-get)
- 屏蔽headers
- random headers
- 屏蔽ip
- http proxy pool
- tor
- javascript加载
- Selenium+(PhantomJS/Chrome/Firefox…)
- 内容加密
- Reverse Engineering
- https
- 反爬虫的哲学